Build 2023 では珍しく App Service のアップデートもいくつか発表されました。これまでは Build のようなイベントと関係ないタイミングでアップデートが発表されることが多かったので意外でした。
とはいえ Build 前に発表されたものが半分ぐらいと、新規のものが残り半分という感じです。
現地でも App Service の Q&A セッションがあり、そこでも以下のようにアップデート内容が公開されていたのですが、どれもちょっとずつ内容が違っていて多少混乱します。特に診断周りの AI-powered 対応は Q&A セッション内でしか公開されていない気がします。

Expert ブースで表示されていた同じスライドには診断周りの記述がなかったので、若干不安定です。
今回発表されたアップデートには App Service でアーキテクチャを考える上でかなり重要なものもあるため、例によって重要だと考えている点についてアップデート内容をまとめておきます。
- Premium V3 の新しい SKU P0v3 / P*mv3 が GA
- Automatic Scaling の Azure Portal サポートがプレビュー
- .NET 8 / Node.js 20 / Python 3.12 / PHP 8.3 の Early Access が間もなく
- 複数の App Service Plan を 1 つの Subnet へ統合サポートが間もなく
- 受信 HTTP トラフィックの IPv6 サポートが予定
- Minimum TLS Cipher Suites 設定の Azure Portal サポート
- TLS 1.3 と E2E の TLS 暗号化サポートが間もなく
- カスタムエラーページがプレビュー
個人的には診断ツールが AI によって強化されるのが楽しみですが、今のところ有効化されている気配を感じないのでまた別途確認しようと思っています。
何回も書いていますが App Service の診断ツールは現時点でも強力なのでサポートに聞く前に開きましょう。
Premium V3 の新しい SKU P0v3 / P*mv3 が GA
App Service の中でも最新の SKU となる Premium V3 の中でも、非常にコストパフォーマンスに優れる P0v3 とメモリ最適化された P*mv3 が GA しました。
先月の時点で GA はしていましたが、発表された時から比べると利用可能なリージョンはかなり増えました。現在では Japan West で P0v3 と P*mv3 が利用可能になっています。
以下のように Azure CLI を叩くと P0v3 と P*mv3 に対応したリージョンを取得可能です。
az appservice list-locations --sku P0v3 --query "sort([].name)" az appservice list-locations --sku P1mv3 --query "sort([].name)"
まだ Japan East には P0v3 と P*mv3 に対応した Scale unit がデプロイされていませんが、ベースとなっている Dasv5 は利用可能になっているので将来的には使えるようになるはずです。
Automatic Scaling の Azure Portal サポートがプレビュー
名前から想像するのは難しいですが Azure Functions のように HTTP トラフィック数によってオートスケーリングする機能です。この機能は割と昔から使えるようになっていたのですが、ようやく Azure Portal から設定できるようになりました。これまでは Azure CLI で設定する必要があったのでかなり手間でした。
機能については Ignite 2022 の時にも書いているので、詳細はこちらも参照してください。
しっかりと検証したことは無かったので、今回の Build では Demo セッションとして "Automatic scaling for Azure App Service web apps" があったので参加してきました。
実際に Automatic Scaling を設定した App Service に対して Azure Load Testing を利用して負荷をかけるというものでしたが、自動的にオートスケールが実行されていく様子を確認できました。利用するには Premium V2 か V3 の App Service Plan が必要になります。

Always On を無効化する必要があるようなので初回リクエストのパフォーマンスが不安ですが、裏に Pre Warm 済みインスタンスが存在するので問題ないようです。
スケールアウトしたインスタンス数は Live Metrics を使えとありますが、Functions Premium と同じであれば Azure Monitor からも確認できるはずです。
.NET 8 / Node.js 20 / Python 3.12 / PHP 8.3 の Early Access が間もなく
最近は定番となりつつ新しい言語バージョンの Early Access での提供ですが、例によって .NET 8 はプレビュー段階から提供されることが確定しています。それ以外には Node.js 20 がこれまでの傾向から行くと LTS ちょっと前のバージョンから利用できるようになるはずです。
Linux 版では Python 3.12 や PHP 8.3 の Early Access も提供されるようなので、組み込みの Runtime Stack を利用している場合にはアップデートを検討してください。
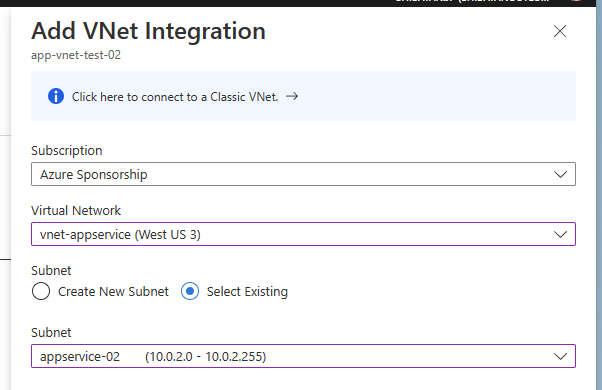
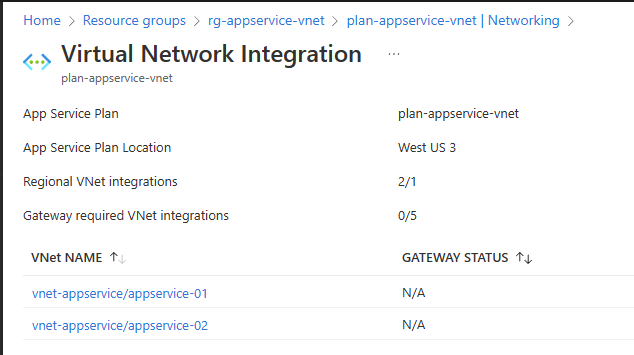
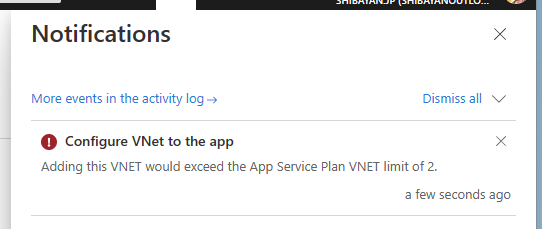
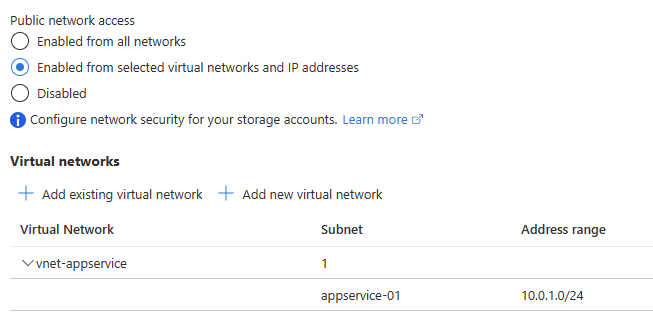
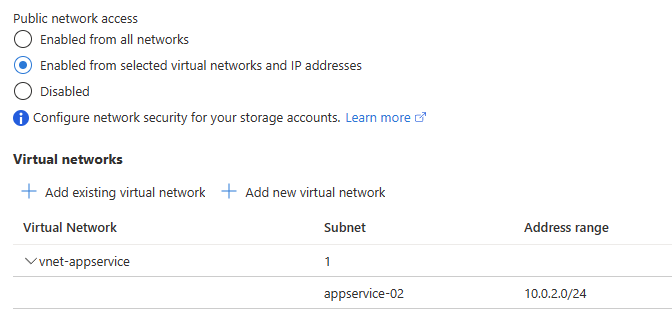
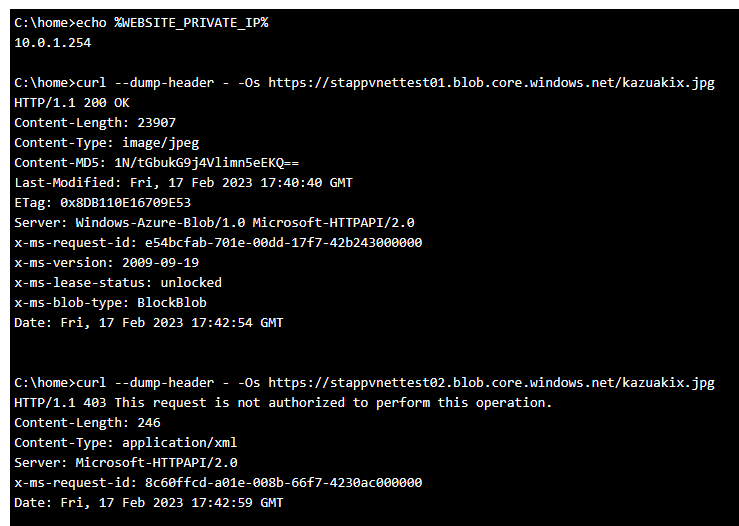
複数の App Service Plan を 1 つの Subnet へ統合サポートが間もなく
これまで 1 つの Subnet には 1 つの App Service Plan しか統合できませんでしたが、間もなく 1 つの Subnet に複数の App Service Plan を統合できる機能がプレビューとなります。
少し前にも Regional VNET Integration 周りは 1 つの App Service Plan が 2 つの Subnet に統合できるように改善されましたが、今回プレビューが予告された 1 つの Subnet に複数の App Service Plan を統合できるようになると、Subnet 設計や Service Endpoint の設定が大幅に簡単になります。
まだ情報が全く出てきていないので制約などは不明ですが、これまでの傾向を見ていると利用するには VMSS Worker で動いている App Service Plan が必要になる気がしています。例によって最初は Premium V3 を指定してデプロイすることが重要なことは変わりません。
受信 HTTP トラフィックの IPv6 サポートが予定
現在は azurewebsites.net は IPv4 しか返しませんが、今後 IPv6 にも対応することが発表されました。既存の App Service でも IPv6 が有効化されるのか、それとも新規にデプロイする必要があるのかなど気になる点は多いのですが、現時点では続報を待ちたいと思います。
個人的には Front Door を前段に置くことが多く、Front Door は既に IPv6 に対応しているので有効化する機会は少ない気がしています。
Minimum TLS Cipher Suites 設定の Azure Portal サポート
Ignite 2022 のアップデート時に試したように、Frontend が YARP + Kestrel にアップグレードされたことで最小の TLS Cipher Suites を指定できるようになりましたが、これまでは ARM レベルでの設定が必要でした。今回のアップデートで Azure Portal から設定できるようになりました。

現時点でもプレビュー扱いにはなっていますが、機能自体はプロダクションで利用できるレベルに達しているようです。今年後半に Frontend が Windows Server 2022 にアップグレードされ、それにより TLS 1.3 へのサポートが追加されたタイミングで GA する予定のようです。
今回で YARP + Kestrel で新しく構築された Frontend は Windows で動いていることが判明しましたね。
TLS 1.3 と E2E の TLS 暗号化サポートが間もなく
先程も書きましたが、ようやく TLS 1.3 サポートが App Service にもやってきます。現在は Application Gateway のみ TLS 1.3 をサポートしているので、App Service での対応は喜ばしいです。そして Front Door でも TLS 1.3 をサポートしてほしい気持ちが高まっています。
YARP + Kestrel は以前から TLS 1.3 に対応していましたが、Windows Server の対応が 2022 からで Frontend のアップグレードが必要になるため時間がかかっていたようです。
そして同時に Frontend と Web Worker 間についても TLS で暗号化されることが予告されました。実は Frontend と Web Worker 間はこれまで非 TLS で通信が行われていましたが、完全に閉じたネットワーク内なのでパフォーマンスを取ったという感じでしょう。
さらっと流していますが、Frontend と Web Worker の関係については YARP + Kestrel への移行記事に図が載っているので、こちらの記事も参考にしてください。
Frontend と Web Worker 間が TLS で暗号化されることで、更にセキュリティを高めることが出来ますし、あくまでも私の想像にはなりますが E2E で HTTP/2 が通るはずなので gRPC 周りの対応が謎の Proxy ポート経由ではなく、素直に利用できるようになる可能性があると考えています。
カスタムエラーページがプレビュー
User Voice で常にトップに上がっていた App Service が返すエラーページのカスタマイズですが、Frontend が YARP + Kestrel にアップグレードされたことでついに対応されました。対応するステータスコードは 403 / 502 / 503 の 3 つになり、HTML をアップロードする形で設定します。

簡単に試してはいますが、403 については比較的簡単に動作を確認できていて、IP Restriction の設定を行うだけの非常にシンプルな確認方法です。難しいのが 502 と 503 で現時点では動作を確認できていません。
503 については App Service を 1 インスタンス構成で再起動すると返されるはずなのですが、シンプルな 503 ページが返ってくるだけでした。また時間のある時に確認しようかと思います。