Build 2024 で Microsoft の AI 戦略が Cloud から Cloud と Edge を組み合わせるように変化したと感じていますが、その決定的なものが今回紹介する AI Toolkit for VS Code だと考えています。元々 Windows AI Studio として存在していた拡張機能の進化バージョンとなります。
AI Toolkit for VS Code を使うと Windows / Windows Arm / Linux 上で現時点では Mistral-7B と Phi-3 mini を簡単に利用することが出来ます。更に Fine-tuning に必要な環境のセットアップやファイルを生成してくれるので、環境構築の手間を大幅に減らすことが出来ます。
名前の通り Visual Studio Code の拡張機能として公開されているので、手持ちの VS Code にインストールすればすぐに Mistral-7B と Phi-3 mini を試すことが可能です。現在公開されているバージョンは macOS に対応していないのが残念ですが、将来的に対応する予定はあるようです。
ドキュメントは非常に少なめですが、まだ機能自体が少ないので十分という感じです。Fine-tuning 以外はドキュメントを読むことなく利用できるレベルなので、使い方で困ることは無いでしょう。
VS Code にインストールするとすぐに GitHub へのログインを要求されますが、これは Model のダウンロード元が GitHub になっているからのようです。特別な挙動では無いので素直にログインすれば終わりです。
コマンドパレットから利用可能なコマンドはそこまで多くは無いですが、知っておくと便利なものがあるので後で紹介します。全体的には Fine-tuning で使われるものが多めです。

AI Toolkit にはいくつかの特筆すべき機能がありますが、まずはサクッと Mistral-7B や Phi-3 mini をローカルにダウンロードして動かすところから試していきます。
Model playground を使ってサクッと試す
AI Toolkit を使う上で最初に行う必要があるのは Model のダウンロードです。Model catalog を選ぶと利用可能な Model 一覧が表示されるので難しくありません。
現在は以下の通り Mistral-7B と Phi-3 mini の 2 つでいくつかのバリエーションが用意されています。現実的にローカル PC で利用できる Model のサイズはこの辺りだと考えられているのでしょう。

Mistral-7B と Phi-3 mini のバリエーションとしては CPU / GPU 向けと Phi-3 はコンテキスト長の違いでいくつか用意されています。GPU とラベルが付いているものは Windows 上では DirectML が使われるようになっています。ちなみに Linux 上で GPU アクセラレーションを使う場合は CUDA を利用する Model になるようですので、NVIDIA の GPU が必要になるみたいですね。WSL 2 で利用する場合も同じだと思われます。
Model のダウンロードが完了すると Models に表示されるので、右クリックメニューから Load in Playground を選ぶとチャット形式でその Model を試せるようになります。

Model Playground の UI は Azure AI Studio とあまり変わらないので、AI Studio を試したことがある方は特に困ることなく利用できるはずです。デフォルトのパラメータは極端な設定なので、試す前に多少の調整は行っておいた方が良さそうです。

見慣れた Chat UI なので使い方は説明不要だと思われますが、ありがちな不具合として IME が有効な状態で変換を確定するために Enter を押すと、途中の文字列がそのまま送信されてしまいます。
そもそも Mistral-7B や Phi-3 mini は日本語が不得意という事情もありますが、入力は英語で行うのが無難です。試しに日本語を送信したところ、やはりイマイチな結果となりました。
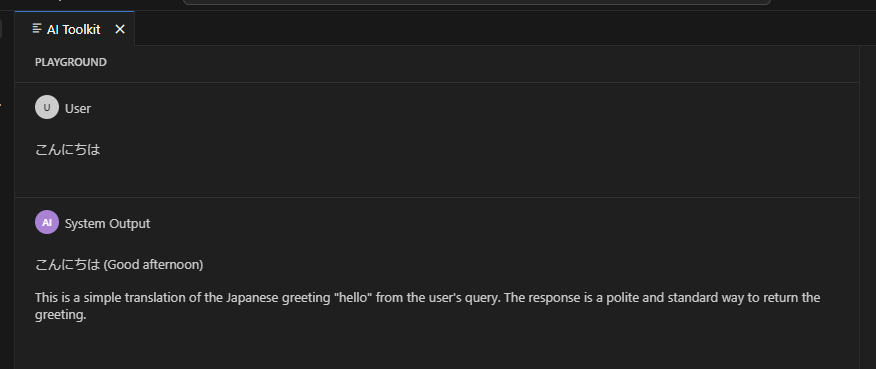
GPT-4o などの LLM では自然な日本語で回答してくれるので、Phi-3 mini の限界を感じることが出来ます。ちなみに AI Toolkit では使えませんが Phi-3 medium の場合は日本語もそこそこ利用出来ます。
ONNX Runtime からダウンロード済み Model を利用する
Model Playground は Model やプロンプトを試すには便利な機能ですが、実際にアプリへ組み込むとなると大きく話が変わってきます。アプリから利用するには以前紹介した ONNX Runtime Generative AI を使って、Model を読み込む必要があります。
ONNX Runtime Generative AI の使い方については、以前書いた以下のエントリを参照してください。
アプリから SLM を利用する際の大きな問題点としては、Model をダウンロードする必要があるということです。将来的には Copilot+ PC の場合はシステムに組み込みで用意されるみたいですが、現状は何とかして Model をダウンロードして読み込む必要があります。
Model 自体のサイズが大きいので分散して管理するのは避けたいですが、AI Toolkit for VS Code はダウンロードされた Model が全てユーザープロファイル以下に保存される仕組みなので、以下のようなコードを書けば AI Toolkit の Model をそのままアプリから利用可能です。
using System.Diagnostics; using Microsoft.ML.OnnxRuntimeGenAI; var systemPrompt = "You are a helpful assistant."; var userPrompt = "Microsoft について説明してください"; var prompt = $"<|system|>{systemPrompt}<|end|><|user|>{userPrompt}<|end|><|assistant|>"; var modelRoot = Environment.ExpandEnvironmentVariables(@"%USERPROFILE%\.aitk\models\"); var modelPath = @"microsoft\Phi-3-mini-4k-instruct-onnx\directml\directml-int4-awq-block-128"; Console.WriteLine("Loading model..."); var sw = Stopwatch.StartNew(); var model = new Model($"{modelRoot}{modelPath}"); var tokenizer = new Tokenizer(model); sw.Stop(); Console.WriteLine($"Model loading took {sw.ElapsedMilliseconds} ms");
実行結果は省略しますが、AI Toolkit では ONNX 形式の Model がダウンロードされるので、当然ながら ONNX Runtime と互換性があるので便利です。アプリからの利用については Copilot+ PC を入手した際に深掘りしていきたいと思います。
OpenAI 互換 REST API 経由で利用する
アプリから ONNX Runtime Generative AI 経由で使うよりもっと簡単に各種 Model を利用したいこともありますが、その場合は AI Toolkit for VS Code が起動時に自動的で公開している OpenAI と互換性のある REST API のエンドポイントを使う方法があります。
以下のドキュメントに記載されているように AI Toolkit は自動的に REST API を公開するので、OpenAI SDK を使っているアプリに少しコードを追加するだけで AI Toolkit の REST API を使うように変更できます。
公式ドキュメントのサンプルコードが若干イマイチだったので、少し書き直して試したのが以下のコードです。DeploymentName に指定する Model 名はそのままダウンロード済みの Model 名になります。
コードの中に出てくる HttpPipelineSynchronousPolicy 周りは Azure SDK 固有の要素なので初めて見た人も多いはずですが、深く考える必要はありません。
using Azure.AI.OpenAI; using Azure.Core.Pipeline; using Azure.Core; var localhostUri = new Uri("http://localhost:5272/v1/chat/completions"); var clientOptions = new OpenAIClientOptions(); clientOptions.AddPolicy(new OverrideRequestUriPolicy(localhostUri), HttpPipelinePosition.BeforeTransport); var client = new OpenAIClient(openAIApiKey: "unused", clientOptions); var options = new ChatCompletionsOptions { DeploymentName = "Phi-3-mini-4k-directml-int4-awq-block-128-onnx", Messages = { new ChatRequestSystemMessage("You are a helpful assistant. Be brief and succinct."), new ChatRequestUserMessage("What is the golden ratio?"), } }; var streamingChats = await client.GetChatCompletionsStreamingAsync(options); await foreach (var streamingChat in streamingChats) { Console.Write(streamingChat.ContentUpdate); } internal class OverrideRequestUriPolicy(Uri overrideUri) : HttpPipelineSynchronousPolicy { public override void OnSendingRequest(HttpMessage message) { message.Request.Uri.Reset(overrideUri); } }
Visual Studio Code を起動後 AI Toolkit を表示すると REST API が公開される仕組みになっているので、その状態でコードを動かしてみると以下のように応答が返ってくることが確認出来ます。

この時に VS Code 側を確認すると REST API の実行ログが出力されているので、どの Model が使われてどのようなプロンプトが実行されたのかを簡単に把握することが出来て便利です。

トークン数や処理時間も表示されているので、性能を把握するのにも役立ちます。意外にこの REST API を公開してくれる機能は使い勝手が良いという認識です。
GPU メモリに読み込まれた Model を解放する
AI Toolkit を使って各種 Model を利用すると GPU メモリに Model が読み込まれますが、VS Code を閉じても GPU メモリが解放されないようです。内部的には別プロセスで推論用の Agent が動いているようで、それをシャットダウンしない限り解放されないようでした。
必要無くなったタイミングでコマンドパレットから Agent のシャットダウンを実行すると解放されます。

シャットダウンを実行すると、以下のように GPU メモリが綺麗に解放されることが確認出来ます。RX 7900 XTX は 24GB のメモリを持っているので余裕がありますが、Model を使っていない時は流石に無駄です。
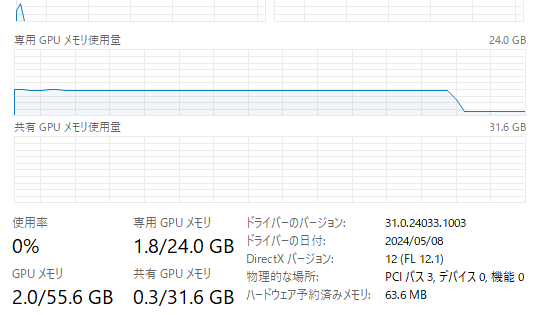
AI Toolkit for VS Code を使って Fine-tuning 以外を触ってきましたが、特別な環境のセットアップは不要で DirectML を使った GPU アクセラレーションも効くのはかなり便利でした。
Fine-tuning も試してみたいと思っていますが、唯一持っている NVIDIA GPU を積んだマシンが不調なのでまた別の機会で試すことにします。