Build 2024 で発表された Cosmos DB のアップデートの中でも注目度の高い Vector Search (Preview) について、実際に試して深堀しておきました。これまで Azure で Vector Search を実行するにはコストが高い割に SLA の低い AI Search を使う必要がありましたが、Cosmos DB for NoSQL が Vector Search に対応したことで情勢が大きく変わろうとしています。
基本となるデータストアである Cosmos DB が Vector Search に対応したことで、追加のインデックスとしての AI Search を使う必要がなくなるため、Vector Search の実行結果として Cosmos DB に保存されている全てのデータを取得できるというのは大きなメリットです。もちろん Cosmos DB の全ての機能が利用できるため、スケーラビリティとパフォーマンスは保証されているので安心な上に、非常に小さなコストで実現出来るようになっています。
特に大規模なシナリオに対応するために DiskANN ベースの Vector Index がサポートされているため、これまで AI Search では非常に高コストになってしまっていたシナリオにも難なく対応できます。DiskANN については公式ブログや Microsoft Research でも紹介されているので、興味がある方はこちらも参照してください。
基本的な Vector Search の使い方については、以下の公式ドキュメントに全てまとまっているのでここを読めば動くものを用意できます。レベルの高い日本語のドキュメントも最初から用意されているので、いつも通り安定の Cosmos DB チームという感じです。
Cosmos DB for NoSQL の Vector Search で気になっている点が RU の消費周りになるので、主にそのあたりについて確認していきます。言語は C# のみで確認していますが、他の言語でもほぼ同じになるはずです。
サンプルとして Cosmos DB に投入するデータはこのブログの全アーカイブとなります。
新しく Cosmos DB アカウントを作成する
まずは Vector Search を有効化したアカウントを用意するわけですが、現状では Vector Search を有効化する場合には、新規に Cosmos DB アカウントを作成するのが無難です。他の Features を有効化していると Vector Search の有効化が出来ないので、クリーンな状態で構築した方が結果として早いです。

有効化が終われば Vector Search に必要な設定を行った Container が作成できるようになります。
ちなみにこの設定は Content Vector Policy と Vector Index の設定を行うための機能有効化で、SQL を使った Vector Search 自体の実行とは関係ないようです。
Vector Policy 付きの Container を作成する
Vector Search を有効化した後は Azure Portal から新しく Container を作成していきます。現状の Vector Search の制約としてデータベース共有スループットは使えないため、作成時に "Share throughput across container" のチェックを外すと Container Vector Policy の設定が表示されます。
この Container Vector Policy で特定プロパティに対して次元数やデータ型などを設定することで、後述する Vector Index の作成が可能となります。

Container Vector Policy を定義すると Vector Index の作成が可能になりますが、実は Cosmos DB の Vector Search では Vector Index の作成は必須ではありません。当然ながら効率は悪くなりますが Vector Index 無しでも動作しますし、何なら Container Vector Policy 無しでも動作しますので、Vector Index を作成するために必要な情報が Container Vector Policy と考えてもらって問題ありません。
Vector Index の設定については対象となる Content Vector Policy を定義したプロパティと、前述した DiskANN などの種類を指定する形になります。Vector Index の種類については公式ドキュメントを参照してください。
現状では DiskANN はフォームからの申請が必要で、自分の手持ちのアカウントでは有効化されていないため試せていませんが quantizedFlat は DiskANN と同じ量子化アルゴリズムを使った flat な Vector Index なので、DiskANN と比べて極端に性能が悪いということはありません。大規模な場合には DiskANN が圧倒的に有利になるということのようです。
今回は以下のようにシンプルな Content Vector Policy と Vector Index を定義しました。Vector に関連する設定は Container の作成時にしか指定できないので、設定を忘れてしまった場合には Container を作り直す必要があるので注意が必要です。
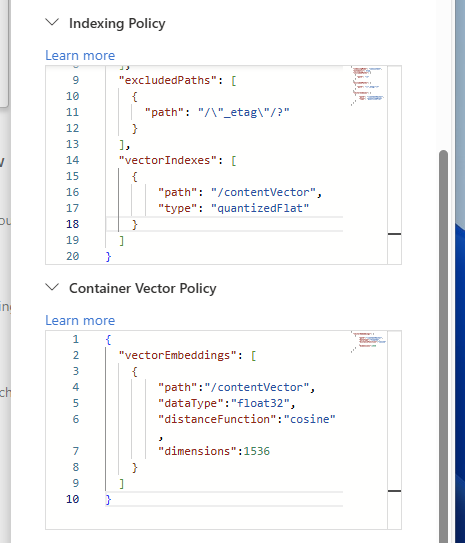
よく使われている OpenAI の text-embedding-ada-002 を使うときの設定になっているので、他の Embedding 向けのモデルを使う際には次元数やデータ型を調整してください。
これで Vector Index を持った Container が作成できたので、後はデータを投入してクエリを投げるだけです。
Embedding を実行し Cosmos DB に保存する
Container Vector Policy と Vector Index を持つ Container を作成してしまえば、後はこれまでの Cosmos DB と同じ使い方で Embedding 結果の Vector を投入するだけです。まずは Azure OpenAI Service と Cosmos DB を利用するために必要な初期化コードから紹介しておきます。
以下の通り Cosmos DB に関係する部分はこれまでと全く変わらないことが分かるはずです。
using Azure.AI.OpenAI; using Microsoft.Azure.Cosmos; var openAIClient = new OpenAIClient(new Uri("https://***.openai.azure.com/"), new Azure.AzureKeyCredential("<API_KEY>")); var connectionString = "<CONNECTION_STRING>"; var cosmosClient = new CosmosClient(connectionString, new CosmosClientOptions { SerializerOptions = new CosmosSerializationOptions { PropertyNamingPolicy = CosmosPropertyNamingPolicy.CamelCase } }); var container = cosmosClient.GetContainer("my-database", "vector-sample");
今回サンプルとして Cosmos DB に投入するデータは、このブログのアーカイブとなるため、データ型は以下のようにシンプルなクラスで表現しています。そして名前の通り ContentVector が Embedding 結果の Vector を保存する float の配列になっています。
public class BlogEntry { public string Id { get; set; } public string Title { get; set; } public string Content { get; set; } public float[] ContentVector { get; set; } }
ブログのデータは適当にエクスポートしたものを上記の型に詰めなおしたものを用意するので、後は以下のコードのように GetEmbeddingsAsync を呼び出して Vector を生成して Cosmos DB に追加するだけです。
地味に Embedding プロパティが ReadOnlyMemory<float> として定義されているので ToArray が必要になるのが嫌ですが、Cosmos DB SDK が ReadOnlyMemory<T> を上手く扱ってくれないので仕方ありません。*1
Embeddings embeddings = await openAIClient.GetEmbeddingsAsync(new EmbeddingsOptions { DeploymentName = "text-embedding-ada-002", Input = { blogEntry.Content } }); blogEntry.ContentVector = embeddings.Data[0].Embedding.ToArray(); var response = await container.UpsertItemAsync(blogEntry, new PartitionKey(blogEntry.Id)); Console.WriteLine($"{response.RequestCharge} RUs");
このコードを実行すると Cosmos DB に 1536 次元の float 配列が投入されますが、なんと書き込みに必要な RU が 279.62 RU と非常に高くなってしまいました。JSON のサイズとしては多く見積もっても 2KB 程なので理論上は 10 RU 前後で書き込めるはずです。
書き込みに 300 RU 近くかかってしまうと Cosmos DB で Vector Search が使えると言っても、低コストでの運用が非常に難しくなるので大幅に下げる必要が出てきます。

これまでの Cosmos DB を運用してきた経験から、JSON のサイズが小さい割に書き込み RU がかかる原因が、デフォルトの Index が全プロパティに対して作成されることにあると分かっているので、以下のように Index Policy を修正し contentVector 以下を全て除外するように設定します。
Index Policy から contentVector を除外しても Vector Index には影響しないため、これで無駄なプロパティに対して Index を構築する必要がなくなるため RU が下がるはずです。
{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*" } ], "excludedPaths": [ { "path": "/contentVector/*" }, { "path": "/\"_etag\"/?" } ], "vectorIndexes": [ { "path": "/contentVector", "type": "quantizedFlat" } ] }
Container の Index Policy を修正した後に、再度同じコードを実行してみると今度は 11.05 RU と劇的に書き込みコストが下がることを確認しました。
これは概ね予想された通りの書き込みコストなので、十分許容できる範囲だと考えています。

ドキュメントには Index Policy のチューニングについては記載されていないので、念のため Cosmos DB チームに問題が無いのか確認を取っている最中です。理論上は問題ないはずですし、書き込みコストが 1/30 近く削減出来るのは大きいので最初から適用しておきたい部分です。
SQL を使って Vector Search を実行する
AI Search の場合は Vector Search を実行するには専用のフィールドを使う形でしたが、Cosmos DB では SQL をそのまま使うので WHERE を使ったフィルタ含めシームレスに扱うことが出来ます。
Cosmos DB の Vector Search 実装のコアとなる部分は VectorDistance 関数となります。この関数を SQL の ORDER BY で利用する事で Vector Search が実現されます。
AI Search に比べるとプリミティブな機能が提供されているので、例えば Vector Search 結果のスコアについては自前で SELECT 文で書く必要があるなど少し手間はあります。公式ドキュメントにもあるように LINQ には VectorDistance 的なメソッドが用意されていないため、SQL で書かないといけないのも手間です。
とはいえ、Vector Search の利用パターンはべらぼうに多いわけでもないため、そこまで SQL を書く手間は発生しないと考えています。将来的に LINQ でも書けるようになると嬉しいといったレベルの話です。
実際に Vector Search を使ってこのブログの記事に対する類似検索を行っていくわけですが、SQL で実行した VectorDistance 関数の結果を類似検索のスコアとして返したいので、以下のように Score プロパティを追加したクラスを用意しました。
public class BlogEntryWithScore : BlogEntry { public float Score { get; set; } }
後は入力文字列を text-embedding-ada-002 で Embedding した結果を Cosmos DB のクエリにパラメータとして渡して、これまで通りの SQL 実行を行えば Vector Search として動作します。以下のサンプルでは 10 件だけ取得するようにしています。
Embeddings result = await openAIClient.GetEmbeddingsAsync(new EmbeddingsOptions { DeploymentName = "text-embedding-ada-002", Input = { "App Service のパフォーマンスとコストの最適化方法" } }); var query = new QueryDefinition("SELECT TOP 10 c.title, VectorDistance(c.contentVector, @embedding) AS score FROM c ORDER BY VectorDistance(c.contentVector, @embedding)") .WithParameter("@embedding", result.Data[0].Embedding.ToArray()); var iterator = container.GetItemQueryIterator<BlogEntryWithScore>(query); while (iterator.HasMoreResults) { var blogEntries = await iterator.ReadNextAsync(); if (blogEntries.Count == 0) { break; } foreach (var blogEntry in blogEntries) { Console.WriteLine($"{blogEntry.Score}: {blogEntry.Title}"); } Console.WriteLine($"{blogEntries.RequestCharge} RUs"); }
実際にこのコードを実行すると、それっぽい結果が返ってきていることが分かります。主にパフォーマンス部分が重視されているように見えますが、App Service に関係する内容が取得出来ています。
クエリにかかったコストも 10.3 RU と非常に低く優秀な結果となりました。これぐらいのコストであればカジュアルに実行しても何ら問題ないレベルに収まっています。

追加で Vector Index の効果を確認するために、Vector Index を定義していない別の Container を作成して実行してみたところ、クエリのコストが 103.63 RU と 10 倍にも増えてしまいました。Cosmos DB の Vector Search は Vector Index が無くても動作しますが、コストが非常に高くなるというのは注意点です。

用意できたデータでは物理パーティションを複数作るには足りなかったので、大規模なデータでの Vector Search については検証が足りていませんが、Build で実際に開発チームに確認を取った限りではパーティションキーの指定は Vector Search でも重要となっていて、クエリコストを下げるのに役立つという話でした。
今回の検証は全て上限 1000 RU のオートスケールで行っていますが、Index Policy を最適化した後では消費された RU は常に 100 RU となっていたため、信頼性の高いデータストアでの Vector Search を月 1500 円程度で開始出来ます。Cosmos DB for NoSQL の Vector Search を使うことで AI Search に比べると劇的なコストダウンを実現出来そうです。
*1:JSON シリアライザを System.Text.Json に変更するとワンチャンいけるかも