去年リリースされた Cosmos DB SDK v3.18.0 から Point Read のような API で複数項目を 1 回のメソッド呼び出しで行える ReadMany API が追加されています。
Point Read のような API デザインなので Id と対応した PartitionKey 両方の指定が必要です。
API としては以下の PR にもあるように、Tuple として Id と PartitionKey のコレクションを渡すと対応する項目をコレクションで返してくれるという、非常に分かりやすいものになります。
パッと見は Point Read を単純に並列で実行してくれているような API になっていますが、ReadMany API は効率的に取得が行えることがアピールされているので、どのくらい効率的なのか気になったので試しました。
元データとしては以下のようなコードを書いて、10000 件 Cosmos DB に投入しています。パーティションキーの範囲は 0-49 の 50 個になるように調整しています。
var container = cosmosClient.GetContainer("Sample", "TodoItems"); var tasks = new Task[10000]; for (int i = 0; i < 10000; i++) { var todoItem = new TodoItem { Id = $"todoitem-{i}", Title = $"Sample Title {i}", Body = $"Sample Body {i}", User = new User { Id = $"user-{i % 50}", Name = $"User Name {i % 50}" } }; tasks[i] = container.CreateItemAsync(todoItem, new PartitionKey(todoItem.User.Id)); } await Task.WhenAll(tasks); public class TodoItem { public string Id { get; set; } public string Title { get; set; } public string Body { get; set; } public User User { get; set; } } public class User { public string Id { get; set; } public string Name { get; set; } }
こういった大量データの追加は Bulk を有効化して Task ベースで非同期にするだけで、簡単に Cosmos DB のスループットを最大限に使い切ってくれるので高速です。
素直に Point Read を並列化する
単純に考えると Cosmos DB は Point Read を使うと一番 RU 少なく取得が出来るので、これを並列化すれば複数項目を効率よく取得できそうな気がしますね。
以下のようなコードを書くと、Point Read を並列実行させて複数項目を簡単に取得できます。
var container = cosmosClient.GetContainer("Sample", "TodoItems"); var tasks = list.Select(x => container.ReadItemAsync<TodoItem>($"todoitem-{x}", new PartitionKey($"user-{x % 50}"))); var result = await Task.WhenAll(tasks);
これで並列実行は出来ますが、1 項目を取得するのに 1 つのリクエストが投げられるため、ネットワークレイテンシの影響をかなり受けてしまうので、効率はあまり良くないです。
ここでいうところの list に含まれる数が非常に多くなると、マシンのリソースを大量に消費してしまいますが、.NET 6 から追加された Chunk を使うとバッチ的に処理出来ます。
var container = cosmosClient.GetContainer("Sample", "TodoItems"); var result = new List<ItemResponse<TodoItem>>(); foreach (var chunk in list.Chunk(100)) { var tasks = chunk.Select(x => container.ReadItemAsync<TodoItem>($"todoitem-{x}", new PartitionKey($"user-{x % 50}"))); result.AddRange(await Task.WhenAll(tasks)); }
当然ながら一部直列処理になるので全体としての処理時間は伸びますが、マシンリソースを食い尽くしてしまって、逆に遅くなるという事態を避けることが出来ます。
バッチでまとまった単位で処理したとしても、ネットワークレイテンシの影響を減らすことは出来ません。ただし消費される RU は一番少ないという期待が持てます。
SQL を使って論理パーティション単位で取得する
Cosmos DB では Point Read だけではなく SQL を使ったクエリを実行することが出来るので、クエリを使うことで 1 回のリクエストで複数項目を取得できます。
ここで重要になるのはクロスパーティションクエリを回避するように、クエリを実行する必要があるという点です。従ってパーティションキー単位でグループ化してから実行する方法を選びます。
var container = cosmosClient.GetContainer("Sample", "TodoItems"); var items = list.Select(x => ($"todoitem-{x}", new PartitionKey($"user-{x % 50}"))).ToArray(); var tasks = new List<Task<(IReadOnlyList<TodoItem>, double)>>(); foreach (var group in items.GroupBy(x => x.Item2)) { tasks.Add(LinqQueryableByPartitionKeyAsync(container, group.Select(x => x.Item1), group.Key)); } var result = await Task.WhenAll(tasks); async Task<(IReadOnlyList<TodoItem>, double)> LinqQueryableByPartitionKeyAsync(Container container, IEnumerable<string> idList, PartitionKey partitionKey) { var iterator = container.GetItemLinqQueryable<TodoItem>(requestOptions: new QueryRequestOptions { PartitionKey = partitionKey, MaxItemCount = 1000 }) .Where(x => idList.Contains(x.Id)) .ToFeedIterator(); var result = new List<TodoItem>(); var requestCharge = 0.0; do { var response = await iterator.ReadNextAsync(); requestCharge += response.RequestCharge; result.AddRange(response); } while (iterator.HasMoreResults); return (result, requestCharge); }
この例では LINQ を使って Contains を条件式に指定していますが、SQL の IN に自動で変換されるようになっています。さらにパーティションキー単位で並列実行することで、処理時間の短縮を狙います。
明示的にパーティションキーを指定しているので、クロスパーティションクエリとして実行されません。
ReadMany API を使って取得する
最後は今回取り上げる ReadMany API を使って取得する例です。API としては Point Read とほぼ同じで、 Id と PartitionKey の Tuple をコレクションとして渡しているだけです。
var container = cosmosClient.GetContainer("Sample", "TodoItems"); var items = list.Select(x => ($"todoitem-{x}", new PartitionKey($"user-{x % 50}"))).ToArray(); var result = await container.ReadManyItemsAsync<TodoItem>(items);
前にも書いたように、API 的には Point Read を並列実行してくれるように見えます。本当に効率的に取得できるのか若干怪しい気もしますが、ここまで紹介した 3 つの方法を実際に動かして試します。
実行結果と考察
単純に Id が 100 から 299 までの 200 件分の項目を取得した結果が以下になります。処理時間は複数回実行していないので、参考程度に捉えておいてください。
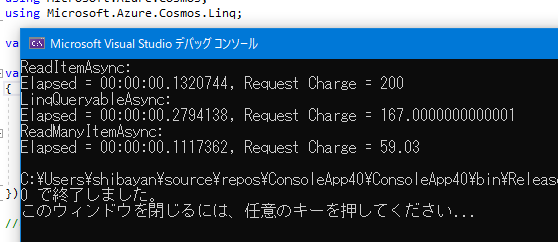
一番 RU の消費が少ないと思われた Point Read の並列化が一番多い結果となりましたが、Point Read では 1 項目読み取る際に 1 RU 以上が絶対に消費されるので、200 件分取得したので 200 RU 消費されているという単純な結果です。これが 1KB 以上のデータではもちろん変わってきます。
SQL を使って論理パーティション単位での取得した場合は Point Read の並列化よりは少なくなっていますが、この例では ReadMany API を使った方法が圧倒的に効率が良いです。
正直なところ、Cosmos DB から任意の項目を取得する方法は Point Read か SQL しかないので、SQL と ReadMany API で大きな差が付くのは考えにくいのですが、その答えは以下の実装にありました。
結論から言うと ReadMany API は SQL を使って複数項目を取得していますが、クエリの実行が論理パーティション単位ではなく物理パーティション単位で行われています。
実際に発行されるクエリはパーティションキーが /id かそれ以外で変わりますが、概ね以下のようなクエリが生成されて Cosmos DB で実行されています。
-- パーティションキーが /id の場合 SELECT * FROM c WHERE c.id IN (...) -- パーティションキーがそれ以外(この例では /pk)の場合 SELECT * FROM c WHERE (c.id = '...' AND c.pk = '...') OR (c.id = '...' AND c.pk = '...') OR ...
パッと見はクロスパーティションクエリになっていて、パフォーマンスに影響が出そうですね。
ついでに RequestHandler を使って SQL を使って論理パーティション単位で実行した時と、ReadMany API を使って実行した時のリクエストヘッダーをキャプチャしたのが以下の画像です。
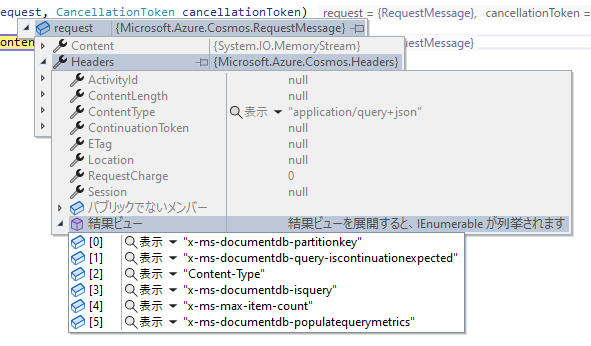
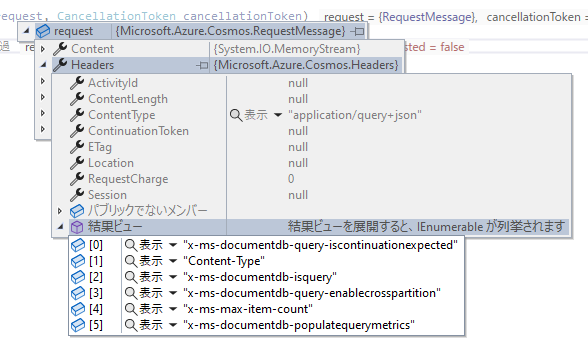
上の論理パーティション単位で実行した場合は、リクエストヘッダーでパーティションキーが設定されていますが、下の ReadMany API を使って実行した場合にはクロスパーティションクエリが有効化されています。
クロスパーティションクエリを使っている ReadMany API の方が消費 RU が少ないのは疑問に感じると思いますが、Cosmos DB の同一物理パーティション内で完結するクロスパーティションクエリの場合は低コストになります。この辺りは以下のドキュメントに記載されています。
じゃあクロスパーティションクエリを避ける必要はないと考える人もいるかもしれませんが、利用者側では特定のパーティションキーがどの物理パーティションに入っているか知る方法が存在しないので、これまで通りパーティションキーを明示的に指定するのは重要です。
ReadMany API はパーティションキーがどの物理パーティションに入っているか知っているので、効率の良い物理パーティション単位での実行が出来るという仕組みです。ちょっとズルいですね。
ちなみに ReadMany API が全てのユースケースで最適かと言われるとそうではありません。取得したい項目のパーティションキーの偏りがほぼ存在しない場合は、素直に SQL を書いた方が消費 RU は少なくなります。
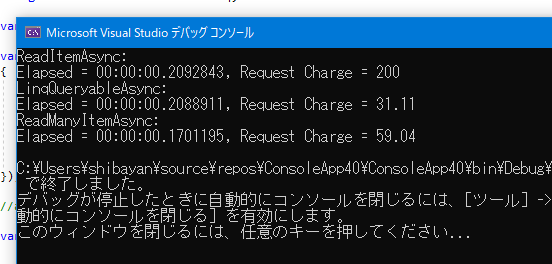
このように 1 つの論理パーティションに対してのクエリは SQL の IN を使う方法が最適なことが分かりますね。ReadMany API はクロスパーティションクエリかつ、若干複雑なクエリを使っているのでその分のコストが増えているようです。
Cosmos DB の論理パーティション・物理パーティション・Change Feed はかなり面白く、内部構造を知っているとパフォーマンスの更なる追求とスケーリングが実現できるので、どこかでまとめたいと思います。