Azure Storage の Blob は大量のデータをスケーラブルかつ安く保存することに特化されているのと、実際には Data Lake Storage Gen 2 以外は名前空間を持っていないので、一般的なファイルシステムのように特定ディレクトリ以下のファイル数やサイズなどの情報は簡単には取れないのですが、Blob Inventory を使うと日次や週次で Blob のデータを CSV や Parquet で作成してくれます。
公式ドキュメントにもあるように一般的には Synapse Analytics と組み合わせて SQL ベースでクエリを書いてしまうのが簡単です。ここでも Synapse Analytics Serverless が使えるので低コストで実現できます。
Synapse Analytics を使うとアドホックにクエリを実行して、その時に必要なデータのみ簡単に抽出できるので便利ですが、実際にはある程度自動化する必要があるケースが多いと思います。
自動化のためには Blob Inventory が完了したタイミングで処理を行う仕組みを用意する必要があります。幸運にも Event Grid 経由で完了を知ることができるので、これを使って Azure Functons での自動化を試します。
Blob Inventory ルールを作成する
まずはターゲットとなる Storage Account に Blob Inventory ルールを作成します。複数ルールの作成ができるので、必要に応じて条件をカスタマイズしたルールを追加することができます。
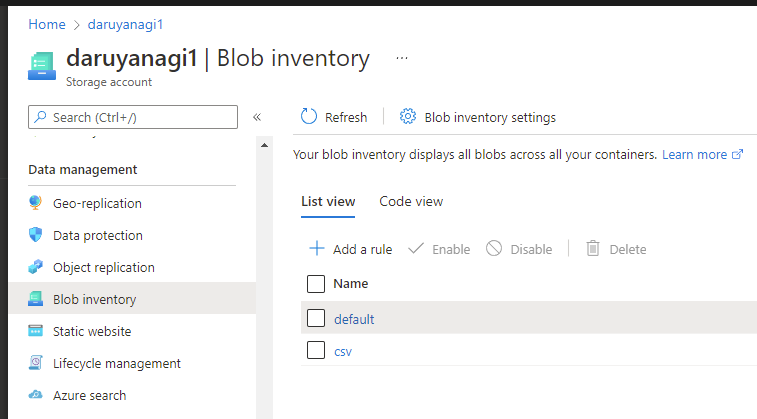
Blob Inventory ルールは細かく設定が可能ですが、重要なのは Blob Inventory に含めるメタデータと出力のファイルフォーマットになります。全てのメタデータを出力してしまうと、ファイルサイズがかなり大きくなってしまうので必要最小限のものを選択します。
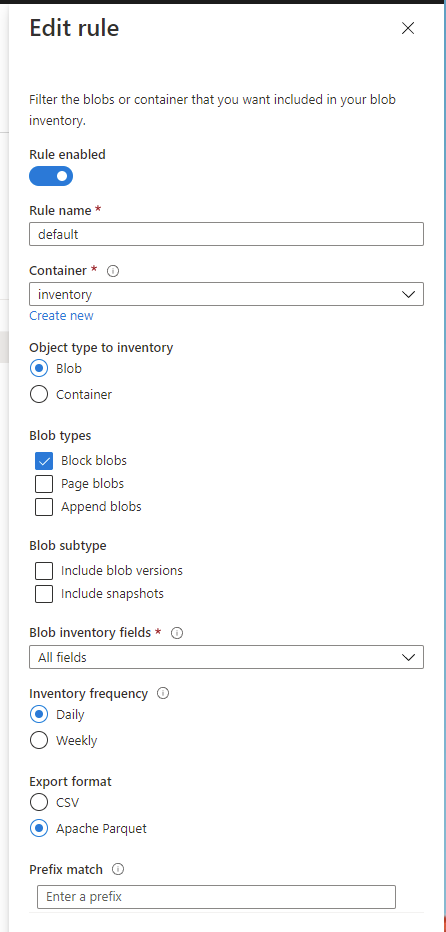
Inventory freqency で日次・週次かの設定が出来ます。実際に処理が動く時間は特に決まっていないようなので、Blob Inventory が完了したタイミングを Event Grid で通知してもらうことが重要になってくるわけです。
(オプション)最終アクセス日時を保存する
これは Blob Inventory とは直接は関係ないのですが、Azure Portal の Blob Inventory 設定から最終アクセス日時の保存を有効化出来るようになっています。
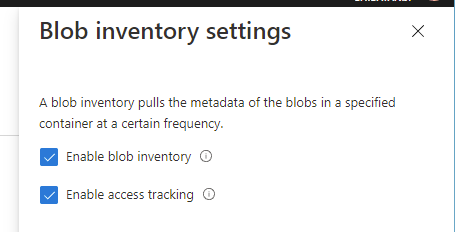
本来なら Lifecycle Managementと組み合わせたいことの方が多い気がしますが、Blob Inventory の結果に最終アクセス日時を含めることが出来るので、必要に応じて有効化しておきます。
ドキュメントにもありますが、メタデータの書き込みが発生するので課金対象になります。書き込み単価は安いですが、Blob へのアクセスが非常に多い場合には高額課金になる可能性もあるので注意しましょう。
Blob Inventory 完了後に Azure Functions で処理を行う
ここまでに何回か言及しましたが、Blob Inventory の処理は日次・週次で実行されますが実行開始時間は定められていないので、基本的には Event Grid 経由で完了したことを通知してもらわないと使いにくいです。
Azure Storage が対応しているイベントを確認すると Blob Inventory Completed が追加されているので、このイベントを購読すると Blob Inventory が完了したタイミングで処理を行うことが出来ます。
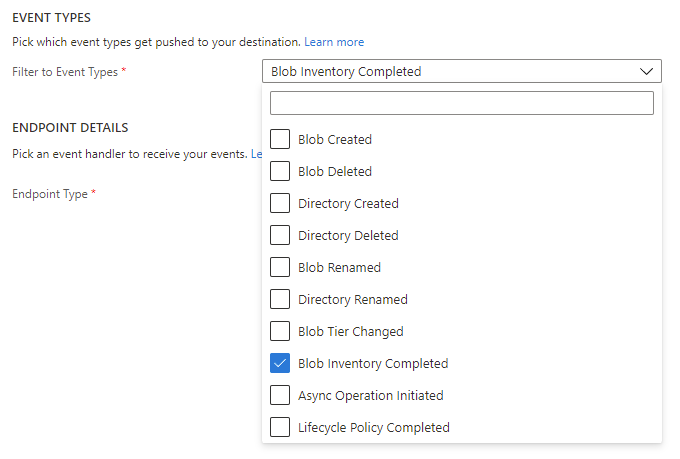
完了時に送信されてくるイベントは以下のようなフォーマットになっています。
イベントに含まれている data の中に Blob Inventory の情報と処理結果のマニフェストファイルのパスが含まれているので、これを読み取ればルールに依存しない処理を作れます。
{ "topic": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/***/providers/Microsoft.Storage/storageAccounts/***", "subject": "BlobDataManagement/BlobInventory", "eventType": "Microsoft.Storage.BlobInventoryPolicyCompleted", "id": "0b0c92c0-6bfe-4a5b-bf1a-bff8cd89144a", "data": { "scheduleDateTime": "2021-12-16T06:19:57Z", "accountName": "***", "ruleName": "default", "policyRunStatus": "Succeeded", "policyRunStatusMessage": "Inventory run succeeded, refer manifest file for inventory details.", "policyRunId": "4acf8dfe-82d0-4868-bb52-262318454482", "manifestBlobUrl": "https://***.blob.core.windows.net/inventory/2021/12/16/06-19-57/default/default-manifest.json" }, "dataVersion": "1.0", "metadataVersion": "1", "eventTime": "2021-12-16T06:31:06Z" }
実際に Blob Inventory によって作成されたファイル情報はマニフェストファイルの方に含まれているので、Event Grid から処理が発火されたらまずはこのファイルを読みに行くようにします。
イベントとマニフェストファイルの JSON スキーマから C# のクラスに変換したのが以下の定義です。
public class BlobInventoryEvent { public DateTimeOffset ScheduleDateTime { get; set; } public string AccountName { get; set; } public string RuleName { get; set; } public string PolicyRunStatus { get; set; } public string PolicyRunStatusMessage { get; set; } public string PolicyRunId { get; set; } public Uri ManifestBlobUrl { get; set; } } public class Manifest { public string DestinationContainer { get; set; } public Uri Endpoint { get; set; } public File[] Files { get; set; } public DateTimeOffset InventoryCompletionTime { get; set; } public DateTimeOffset InventoryStartTime { get; set; } public string RuleName { get; set; } public string Status { get; set; } public Summary Summary { get; set; } public string Version { get; set; } } public class Summary { public int ObjectCount { get; set; } public int TotalObjectSize { get; set; } } public class File { public string Blob { get; set; } public int Size { get; set; } }
多少簡略化していますが、基本的にはこの定義があれば十分処理が行えます。
マニフェストファイルを読み込んでしまえば、後は Blob Inventory 結果のファイルを読み込んで、好きなように処理してしまえば終わりです。ファイルフォーマットには前述したように CSV と Parquet が選べますが、今回は簡単にするために CSV を選び、更に読み込みには以下のライブラリに含まれている DataFrame を使うことにしました。実体としては ML.NET に含まれているライブラリです。
名前の通り pandas の DataFrame によく似たインターフェースを持った C# 実装です。単純に C# で CSV を読むだけなら CsvHelper で十分ですが、読み込んだ後にフィルタなどを行う場合はこちらのが便利です。
今回書いた Azure Functions のコードを以下に載せておきます。マニフェストファイルなどは読み込むために認証が必要なので、Blob SDK 経由で扱う必要があることに注意してください。
public class Function1 { [FunctionName("Function1")] public async Task Run([EventGridTrigger] EventGridEvent eventGridEvent, ILogger log) { // Event Grid のデータを Blob Inventory Event としてデシリアライズ var blobInventoryEvent = eventGridEvent.Data.ToObjectFromJson<BlobInventoryEvent>(new JsonSerializerOptions { PropertyNameCaseInsensitive = true }); var credential = new StorageSharedKeyCredential(Environment.GetEnvironmentVariable("AccountName"), Environment.GetEnvironmentVariable("AccountKey")); // イベントで渡された Manifest ファイルをダウンロード var manifestBlob = new BlobClient(blobInventoryEvent.ManifestBlobUrl, credential); var content = await manifestBlob.DownloadContentAsync(); var manifest = content.Value.Content.ToObjectFromJson<Manifest>(new JsonSerializerOptions { PropertyNameCaseInsensitive = true }); // Manifest に記載された情報から今回生成された CSV ファイルを読み取る var blobServiceClient = new BlobServiceClient(manifest.Endpoint, credential); var containerClient = blobServiceClient.GetBlobContainerClient(manifest.DestinationContainer); var blobClient = containerClient.GetBlobClient(manifest.Files[0].Blob); // 生成された CSV をダウンロードして DataFrame として読み込む var inventory = await blobClient.DownloadContentAsync(); var dataFrame = DataFrame.LoadCsv(inventory.Value.Content.ToStream()); var filtered = dataFrame[dataFrame["Content-Length"].ElementwiseGreaterThan(16 * 1024)]["Name"]; log.LogInformation($"Count = {filtered.Rows.Count}, Values = {string.Join("\n", filtered["Name"].Cast<string>())}"); } }
処理内容としてはファイルサイズが 16KB 以上の Blob の件数を数えて、ファイル名を出力するといった簡単なものです。今回使った Microsoft.Data.Analysis については別で詳しく書こうかと思っています。
この Function をデプロイして、Event Grid のエンドポイントとして指定すれば完成です。
後はしばらく放置して、Blob Inventory が完了するのを待ちましょう。実行されると Application Insights には以下のようなログが出力されるので、正しく動作していることが確認できます。

今回はファイル数が少なかったので CSV を使いましたが、基本的には CSV はファイルサイズが大きくなってしまうので、ファイル数が多い場合は Parquet を使った方がコンパクトかつ高速です。
古い Blob Inventory ファイルを自動で削除する
最後はおまけ的な話になりますが、Blob Inventory で生成されたファイルは放置すれば無駄に溜まり続けていくので、Blob Lifecycle Management を設定して 90 日以上前のファイルは削除するようにしました。
{ "rules": [ { "enabled": true, "name": "inventory", "type": "Lifecycle", "definition": { "actions": { "baseBlob": { "delete": { "daysAfterModificationGreaterThan": 90 } } }, "filters": { "blobTypes": [ "blockBlob" ], "prefixMatch": [ "inventory" ] } } } ] }
既に Blob の Lifecycle Management は利用している人が多いと思うので、ルールを見ていただければすぐに理解できるかと思います。やっていることは特定のコンテナー以下の最終書き込み日時を調べて、それが 90 日以上前のファイルを消すようにしているだけです。