Azure Search が今日 GA になりましたが、GA になったニュースよりも新しい API に追加された機能に注目します。GA になってどう変わるかは、ブチザッキを見ておけば全て理解できます。
2015-02-28-Preview: This is the new “prototype” version where we bring in new experimental features. In this version you will find the enhancements to multilanguage support as well as the new “more like this” feature.
Azure Search is now Generally Available | Blog | Microsoft Azure
the new “more like this” feature と言う部分がとても気になりました。
2015-02-28-Preview API のドキュメントに、もう少し細かく説明が書いてます。
- Natural language processors from Microsoft (the same ones used by Office and Bing) offer greater precision over query results and more languages.
- moreLikeThis is a a query parameter used in Search operations that finds other documents that are relevant to another specific document.
Azure Search Service REST API Version 2017-11-11-Preview | Microsoft Docs
Microsoft が Office や Bing で使っている NLP が Azure Search のアナライザーとして使えるようになりました。まあ、それはインデックスを作るときに ja.microsoft とか指定すればいいので、とりあえず放置します。形態素解析の精度ぐらいの差でしょう。
それよりも注目したいのが moreLikeThis パラメータが検索処理に追加されたことです。moreLikeThis パラメータは、Azure Search のバックエンドの Elasticsearch に実装されている類似ドキュメントの検索を行うための API で、これがついに解放されました。
Elasticsearch の more like this に関しては、クックパッドさんのブログが分かりやすかったです。
つまり Elasticsearch を自分で用意しなくても Azure Search を使えば、同じように関連するドキュメントの検索が簡単に出来るようなりました!素晴らしい!*1
実際に Azure Search を使って、このブログの類似ドキュメント検索を試してみました。クックパッドさんのブログをめっちゃ参考にしました。
Azure Search で類似ドキュメントの検索を試す
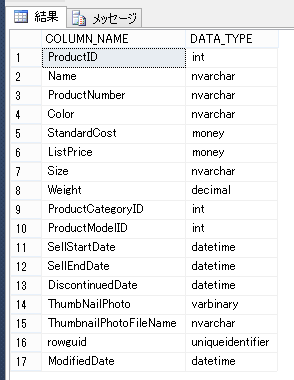
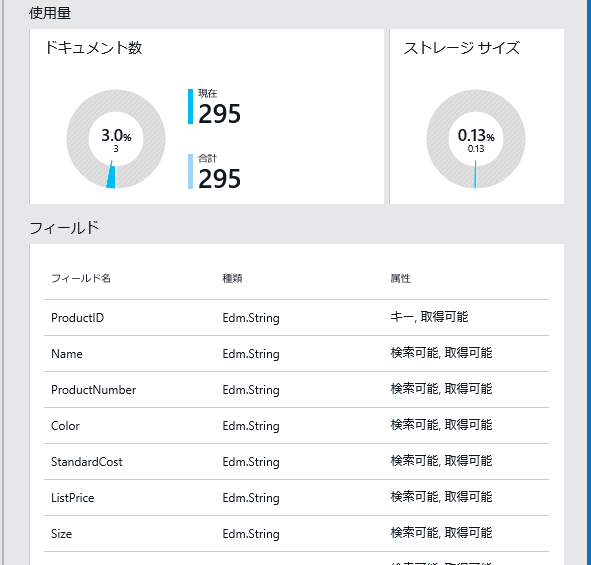
まずはインデックスを作る必要があるわけですが、構造は全く同じ形で用意しました。

英語にしてあるのは SORTABLE が日本語では検索可能と翻訳されていたからです。まだまだプレビュー感があってたまりませんね。
Azure Search が GA したおかげか、アナライザーの設定までプレビューポータルから行えるようになっていてとても便利です。毎回 REST API を叩く必要もなく最高です。

まだプレビューポータルでは ja.microsoft は選べなかったので、Lucene を選びました。
インデックスが出来たので、実際に Azure Search へドキュメントを追加していくのですが、はてなブログのエクスポートは MT 形式でとてもめんどくさいので、Ruby なオリジナルのコードを C# に移植しました。
var content = File.ReadAllText(@"blog.shibayan.jp.export.txt");
var matches = Regex.Matches(content, @"TITLE:\s(.*?)\n.*?STATUS:\s(.*?)\n.*?DATE:\s(.*?)\n.*?BODY:\n(.*?)----\n", RegexOptions.Singleline);
var entries = matches.Cast<Match>().Select(x => new Entry
{
Id = Regex.Replace(x.Groups[3].Value, @"\D", ""),
Title = x.Groups[1].Value,
Body = StripHtml(x.Groups[4].Value)
}).ToArray();
地味に扱いにくいので、XML とか JSON で吐き出して貰いたいものです。
これで全エントリのデータを配列に詰め込めたので、後は今回新しくリリースされた Azure Search の .NET SDK を使って投入します。
var serviceClient = new SearchServiceClient("SEARCH_NAME", new SearchCredentials("ADMIN_KEY"));
var indexClient = serviceClient.Indexes.GetClient("entries");
for (int i = 0; i < (entries.Length / 1000) + 1; i++)
{
indexClient.Documents.Index(IndexBatch.Create(entries.Skip(1000 * i).Take(1000).Select(IndexAction.Create)));
}
API の呼び出し自体は結構素早いですが、インデックスへの投入は非同期で行っているみたいなので、全件処理されるまで少しかかった気がします。
これで、このはてなブログの全エントリデータを Azure Search に投入できました。

とりあえず、ちゃんとインデックスが出来ているか検索して確認しておきます。
var serviceClient = new SearchServiceClient("SEARCH_NAME", new SearchCredentials("QUERY_KEY"));
var indexClient = serviceClient.Indexes.GetClient("entries");
var response = indexClient.Documents.Search<Entry>("抱かれたい男", new SearchParameters
{
Top = 5
});
foreach (var item in response)
{
Console.WriteLine("{0} : {1}", item.Score, item.Document.Title);
}
地味に型付きで検索が出来るのが良いです。いい感じにインデックス周りの処理が書けます。
実行してみた結果は以下の通りです。スコアはあまり高くないですが、まずまずの検索が出来ています。

それでは本題の More Like This API を使って、類似ドキュメントの検索を行ってみます。残念ながらプレビュー API に SDK が対応していないので、例によって RedDog.Search を改造して試します。
類似するドキュメントを見つけたい記事は、以下の Knockout.js について書いたものにしました。
RedDog.Search を改造して moreLikeThis パラメータを取れるようにしただけなので、コードとしては以下のような形になります。moreLikeThis には類似ドキュメント検索をしたい元のキーを渡します。なので、今回の場合は日付ベースの値です。
var connection = ApiConnection.Create("SEARCH_NAME", "QUERY_KEY");
var client = new IndexQueryClient(connection);
var results = await client.SearchAsync("entries", new SearchQuery()
.MoreLikeThis("08192014002348")
.Top(10));
foreach (var item in results.Body.Records)
{
Console.WriteLine("{0} : {1}", item.Score, item.Properties["title"]);
}
実行してみた結果は以下の通りです。ちゃんと Knockout.js に関係する記事を取得出来ています。

今度は別の記事で試してみました。ASP.NET MVC について書いた記事です。
これも同様に moreLikeThis にキーを渡して実行してみました。

ASP.NET に関する記事は多いためスコアは思ったほど高くはないですが、ちゃんと関係する記事のみを取得出来ていることが確認出来ました。
本来なら複雑な処理が必要なところ、とりあえずインデックスにデータを入れておけば使える点、かなり便利だと感じました。是非ともお仕事で使ってみたいので、日本リージョンにデプロイお願いします。