そろそろ NPU を使うとどのくらいの性能が出るのか気になっていたのですが、DirectML の Snapdragon X Elite の NPU 対応は自分の手元では全然動作しなかったので、ひとまずは Qualcomm AI Engine Direct SDK (QNN SDK) を使って NPU を使ってみることにしました。
QNN SDK はネイティブ向けのライブラリのみとなっているので、そのまま使うのではなく ONNX Runtime に用意されている QNN Execution Provider 経由で利用します。
NuGet には QNN を組み込んだビルド済みのバイナリが用意されているので、QNN SDK をダウンロードしてビルドする必要がないため準備が楽です。若干 ONNX Runtime 本体のバージョンより遅れているのが気になりますが、ちゃんとメンテナンスはされているようです。
QNN に最適化された ONNX モデルは Qualcomm の AI Hub で公開されているので、こちらからモデルをダウンロードする形になります。しっかり確認したわけではないですが、基本的に全ての ONNX モデルが NPU で動くわけではなく最適化が必要になるようです。
Qualcomm AI Hub は意外に様々な最適化モデルが公開されていて、Windows on Arm で使われている Snapdragon X Elite 向けのモデルだけではなくモバイル向けのモデルもダウンロード可能です。
ここまでが QNN を使う上での基本的な情報ですので、ここからは実際に C# で ONNX Runtime の QNN Execution Provider を使ってみたいと思います。何を行うべきか悩みましたが、まずは公式のサンプルコードが用意されている ResNet50 を使った画像分類を行ってみます。
以下のドキュメントをほぼそのまま使って試していきますが、AI Hub で公開されている ResNet50 は v2 ではないので入力の正規化周りで少し修正が必要でした。
AI Hub で公開されている ONNX モデルは以下を利用します。いくつかのバリエーションがありますが、可能な限りドキュメントで使っているものに合わせておきます。モデルをダウンロードする際は ONNX Runtime が選択されていることを確認してください。
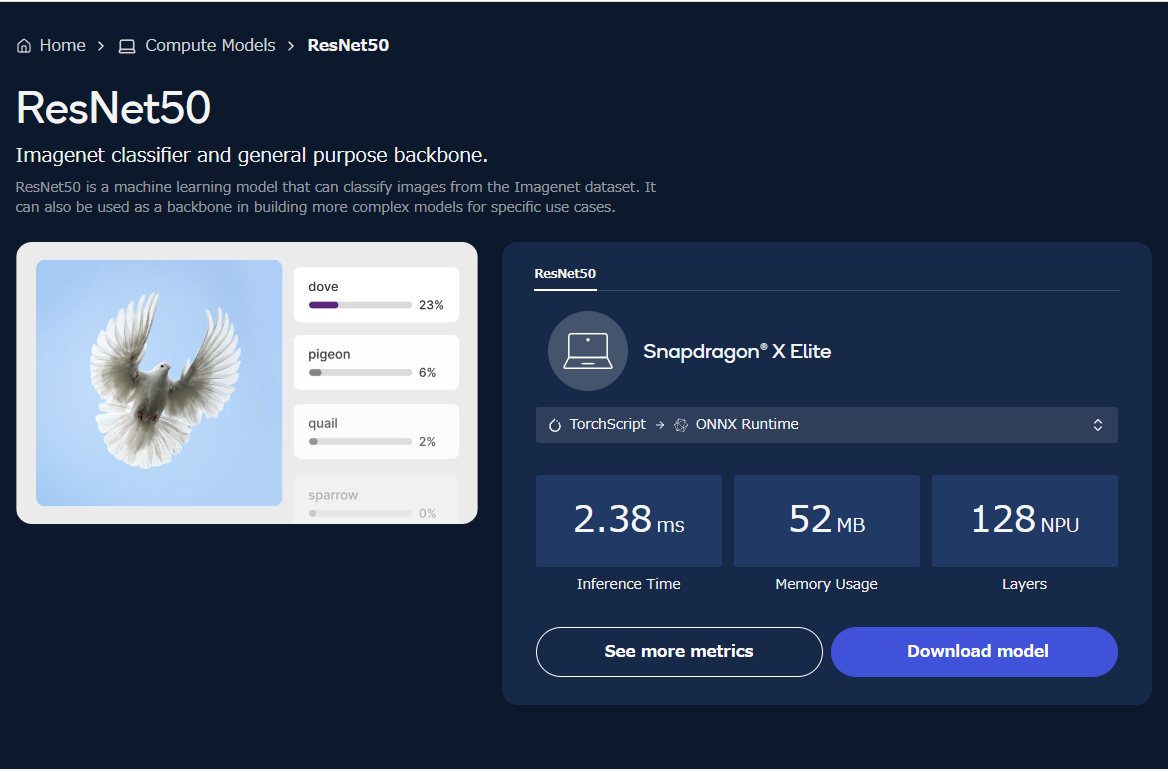
モデル詳細ページにある See more metrics を選ぶと、モデルのメタデータやテストに使用した各種パラメータが確認できるがコードを書く際に便利です。地味に QNN に渡すパラメータが多いので、動作実績のある値がわかるというのは最高です。
今回利用したサンプルコードは以下の通りになります。基本的な流れは ONNX Runtime の ResNet v2 向けサンプルコードとほぼ同じですが、入力画像の正規化処理を削除しつつ QNN Execution Provider を使うように設定を行っています。
using Microsoft.ML.OnnxRuntime; using Microsoft.ML.OnnxRuntime.Tensors; using SixLabors.ImageSharp; using SixLabors.ImageSharp.PixelFormats; using SixLabors.ImageSharp.Processing; // Read paths var modelFilePath = @".\resnet50.onnx"; var imageFilePath = @".\dog.jpeg"; // Read image using var image = Image.Load<Rgb24>(imageFilePath); // Resize image image.Mutate(x => { x.Resize(new ResizeOptions { Size = new Size(224, 224), Mode = ResizeMode.Crop, Position = AnchorPositionMode.Center }); }); // Preprocess image Tensor<float> input = new DenseTensor<float>([1, 3, 224, 224]); image.ProcessPixelRows(accessor => { for (var y = 0; y < accessor.Height; y++) { var pixelSpan = accessor.GetRowSpan(y); for (var x = 0; x < accessor.Width; x++) { input[0, 0, y, x] = pixelSpan[x].R / 255f; input[0, 1, y, x] = pixelSpan[x].G / 255f; input[0, 2, y, x] = pixelSpan[x].B / 255f; } } }); // Setup inputs var inputs = new List<NamedOnnxValue> { NamedOnnxValue.CreateFromTensor("image_tensor", input) }; // Setup QNN using var sessionOptions = new SessionOptions { LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_WARNING, ExecutionMode = ExecutionMode.ORT_SEQUENTIAL, IntraOpNumThreads = 0, InterOpNumThreads = 0, EnableMemoryPattern = false, EnableCpuMemArena = false, GraphOptimizationLevel = GraphOptimizationLevel.ORT_ENABLE_ALL }; sessionOptions.AppendExecutionProvider("QNN", new Dictionary<string, string> { { "backend_path", "QnnHtp.dll" }, { "htp_performance_mode", "burst" }, { "htp_graph_finalization_optimization_mode", "3" }, { "enable_htp_fp16_precision", "1" } }); // Run inference using var session = new InferenceSession(modelFilePath, sessionOptions); using var results = session.Run(inputs); // Postprocess to get softmax vector var output = results[0].AsEnumerable<float>(); var sum = output.Sum(x => (float)Math.Exp(x)); var softmax = output.Select(x => (float)Math.Exp(x) / sum); // Extract top 10 predicted classes var top10 = softmax.Select((x, i) => new Prediction { Label = LabelMap.Labels[i], Confidence = x }) .OrderByDescending(x => x.Confidence) .Take(10); // Print results to console Console.WriteLine("Top 10 predictions for ResNet50..."); Console.WriteLine("--------------------------------------------------------------"); foreach (var t in top10) { Console.WriteLine($"Label: {t.Label}, Confidence: {t.Confidence}"); }
今回のコードの肝は AppendExecutionProvider を呼び出している部分になります。DirectML や CUDA は専用のメソッドが用意されていますが、QNN 向けのメソッドは用意されていないので、プリミティブなメソッドを使って登録する必要があります。
このコードを実行してみると、QNN Execution Provider を追加するタイミングで以下のような例外が発生することがあります。これは QNN 向けの NuGet パッケージに含まれている dll を参照できないことで発生しているので、ビルドされた exe と同じディレクトリに QNN パッケージに含まれている dll をコピーすると、問題なく動作するようになります。
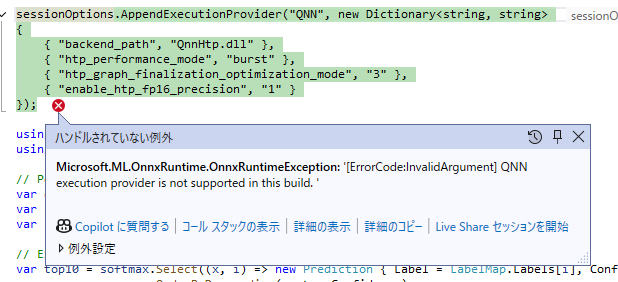
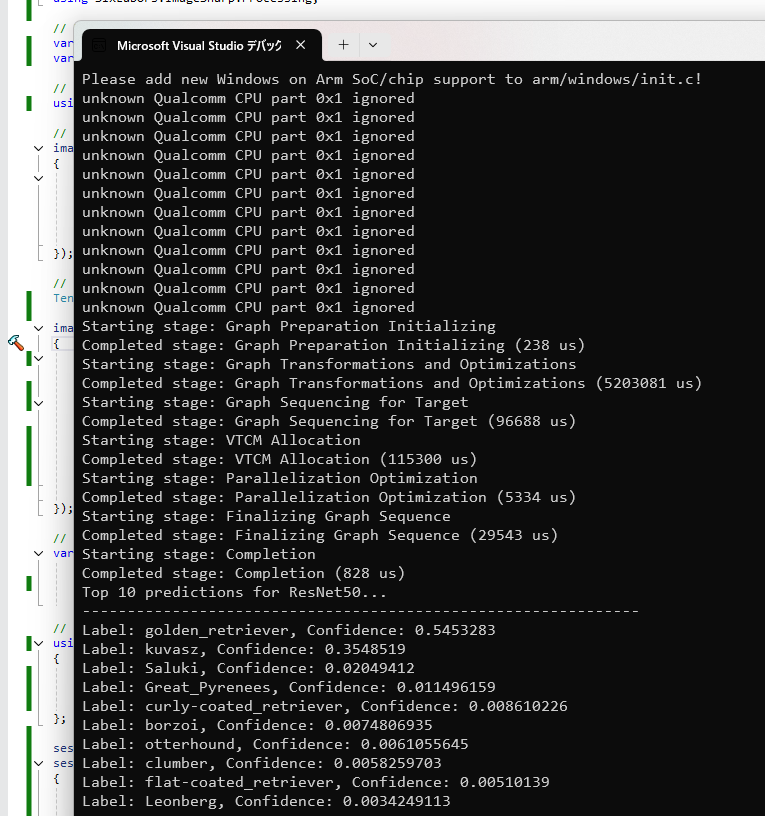
QNN 関連の dll をコピーして実行すると、以下のように警告が出ますが ResNet50 を使った分類結果が出力されます。サンプルの犬の画像を使ったので正しく分類されていることがわかります。
少し気になるのはモデル読み込みが CPU で動かしたときより NPU の方が時間がかかっていることで、NPU 向けの最適化処理が入るようなので、最初から NPU 向けに最適化出来ればベストな気がします。
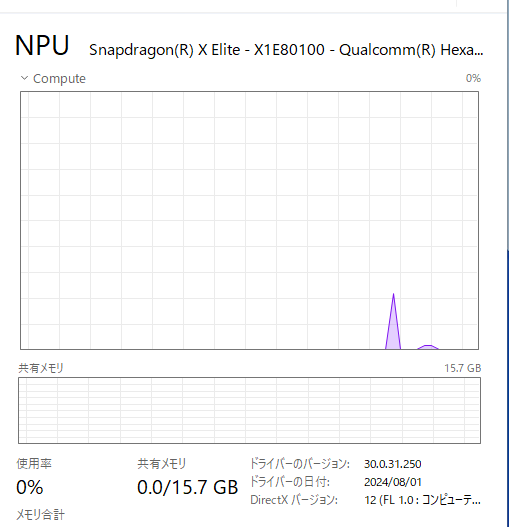
肝心の NPU が使われているかどうかはタスクマネージャーでサクッと確認しました。モデルの読み込み時と推論時で 2 回 NPU が使われていることが確認できました。ResNet50 は負荷が小さいのであまり NPU の効果は感じられない感じでしたが、画像枚数が増えると変わってきそうです。
QNN を直接利用する場合には生成 AI も利用できるらしいので試してみたくなります。個人的にはやはり Phi-3 が NPU で動くようになるのを待っているのですが、Windows App SDK 1.6 でも Phi-Silica 向けの API が公開されなかったなど、なかなか利用可能にならないのでもどかしいです。