以前に ONNX Runtime Generative AI に対応した Phi-3 mini / medium のモデルを利用して、ローカルマシンの DirectML アクセラレーションが効く形で動かしてみました。本命と考えている NPU に最適化された Phi-Silica はまだ利用可能になっていないので、今のところは Phi-3 を DirectML で使うのが現実的な方法です。
その時には公開されていなかった Phi-3 Vision の ONNX モデルがつい最近 Hugging Face で公開されたようなので、今回はマルチモーダルに対応した形で ONNX Runtime Generative AI を使って試してみます。
Phi-3 Vision 128k の DirectML 向け ONNX モデル公開されてた https://t.co/KyiRyX2sVo
— Tatsuro Shibamura (@shibayan) 2024年7月13日
ONNX Runtime から利用する場合には ONNX モデル形式が必要になるのと、DirectML でのアクセラレーションを有効化するには最適化された専用のモデルが更に必要になるため、Hugging Face からダウンロードする場合には気を付ける必要があります。
既に ONNX Runtime Generative AI はバージョン 0.3.0 で Phi-3 Vision などのマルチモーダルへの対応が追加されているので、以下のサンプルを参考にすれば簡単に実行することが出来ます。
前回と同様に DirectML アクセラレーションを利用したいので以下のパッケージをインストールします。このパッケージだけで追加のランタイムなど必要なく DirectML でのアクセラレーションが効くので便利です。早く Copilot+ PC の NPU に対応した DirectML がリリースされて欲しいですね。
ONNX Runtime Generative AI を使って画像を扱うには、事前に入力画像を Tensors に変換する必要があるので、テキストだけを扱う場合に比べると追加の手順が発生します。このあたりは ONNX Runtime が低レベルな API を提供している関係上発生しているだけで、将来的には Azure OpenAI SDK のように使いやすいライブラリが出てきそうな予感です。
Phi-3 Vison の ONNX モデルは事前に Hugging Face からダウンロードしておきます。
using Microsoft.ML.OnnxRuntimeGenAI; var modelPath = @".\Phi-3-vision-128k-instruct-onnx-directml\directml-int4-rtn-block-32"; var imagePath = @".\table.png"; var text = "Convert this image to markdown format"; using var model = new Model(modelPath); using var processor = new MultiModalProcessor(model); using var tokenizerStream = processor.CreateStream(); var images = Images.Load(imagePath); var prompt = $"<|user|><|image_1|>{text}<|end|><|assistant|>"; Console.WriteLine("Processing image and prompt..."); var inputTensors = processor.ProcessImages(prompt, images); Console.WriteLine("Generating response..."); using var generatorParams = new GeneratorParams(model); generatorParams.SetSearchOption("max_length", 3072); generatorParams.SetInputs(inputTensors); using var generator = new Generator(model, generatorParams); while (!generator.IsDone()) { generator.ComputeLogits(); generator.GenerateNextToken(); Console.Write(tokenizerStream.Decode(generator.GetSequence(0)[^1])); }
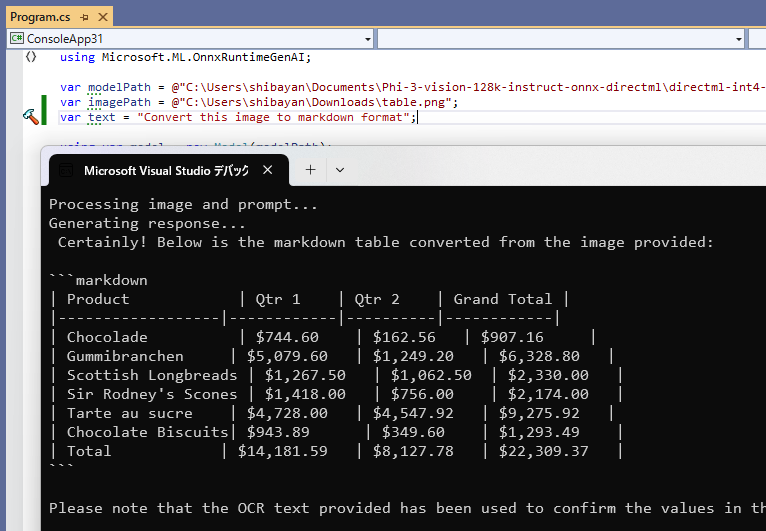
サンプルコードで行っている内容は画像で与えられたテーブルを Markdown に変換するものです。利用しているプロンプトと画像は ONNX Runtime のチュートリアルにあるものをそのまま利用しています。
このコードを実行してみると、以下のように画像で与えられたテーブルを Markdown に変換できていることが確認出来ます。モデルの読み込みが終わってしまえば低レイテンシで応答が返ってくるため、このくらいの処理であれば Phi-3 Vision でも余裕のようです。
追加でプロンプトを変更して、入力画像のテーブルを JSON として出力するように指示を出してみました。シンプルなプロンプトでは何度やっても Markdown に勝手に変換してしまう事象に遭遇しましたが、画像に含まれているデータを JSON とするように明確に指示を出すと上手くいきました。
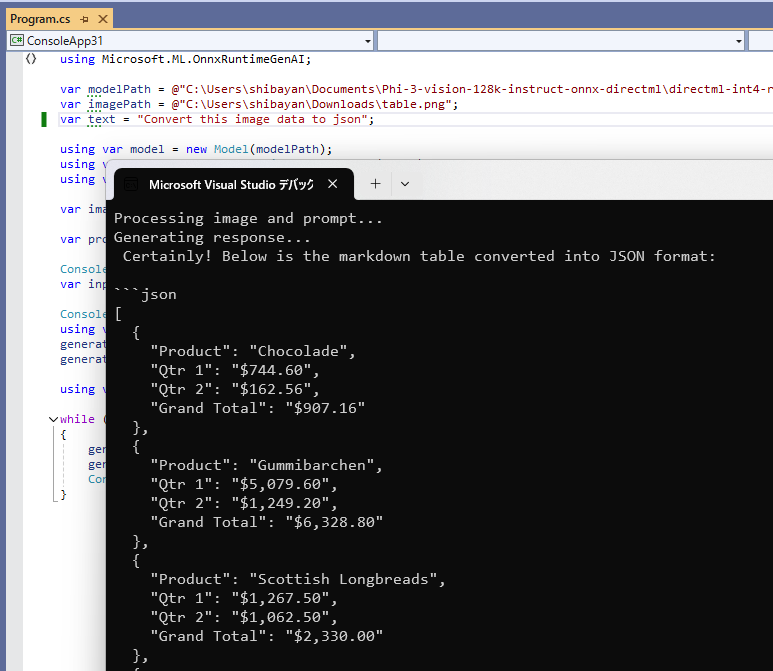
SLM 全般に言えることかもしれませんが、少なくとも Phi-3 の場合はかなり明確に指示を出して、更に制約も付けないと余計な情報まで出力しがちだと感じました。上の例でもプロンプトに結果の JSON だけ出力するように制約を付けています。
最後に以下の画像を入力して、その内容を説明させるようなプロンプトを作成して試しました。ちなみにこの犬は以前実家で飼っていた子になります。

Phi-3 Vision で画像を説明させた結果は以下のようになりました。日本語で出力させようとすると一気に文章が破綻するのですが、英語の場合はそこそこの精度が出ているようです。
The image captures a serene moment of a white dog with a black and red leash, sitting on a gravel surface. The dog's body is angled towards the camera, its head turned to the side, giving us a view of its face. The leash, adorned with a red and black pattern, is untied, suggesting a sense of freedom and relaxation. The dog's tongue is out, adding to the overall calm and relaxed demeanor of the scene. The background is a blur of gravel, providing a stark contrast to the dog's pristine white coat. The image exudes a sense of tranquility and peace, as if the dog is taking a moment to rest and enjoy its surroundings.
僅か 2GB 程度のモデルとは思えない精度と言えるので、モデルの配布と利用が OS に組み込まれるとユースケースが一気に広がるのではないかと思います。
その辺りは Windows Copilot Runtime と Windows Copilot Library に期待したい部分ですね。