Azure Functions の Node.js や Python といった言語ワーカーが動作するタイプでは、これまで HTTP のリクエストとレスポンスを Stream として扱うことが出来なかったので、大容量ファイルのダウンロードやアップロードが効率的に行えないという制約がありました。
この制約は In-Process で動作する C# のみ適用されず、同じ C# でも .NET Isolated を使っている場合は Node.js や Python と同様の制約を受けていましたが、ASP.NET Core Integration の追加によって解消されました。仕組みとしては HTTP だけは Azure Functions Runtime が裏側の言語ワーカー対して、HTTP リクエストをそのままフォワーディングすることで実現しています。
以前の仕組みでは HTTP も一旦は gRPC に変換していたので、どう頑張っても Stream として扱うことが出来ないという事情がありました。ちなみに HTTP フォワーディングには YARP が使われているので信頼性とパフォーマンスの面でも安心です。
この新しい仕組みによって Azure Functions の言語ワーカーでも効率的に HTTP が扱えるようになりましたが、この度 Node.js でも同じ仕組みがサポートされるようになったという話です。現在はプレビュー中ですが、仕組みとしてはシンプルなので GA もそう遠くないでしょう。
C# では ASP.NET Core Integration という形で導入されたので、HTTP リクエストとレスポンスを表す型が変更され移行が必要になりましたが、Node.js の HTTP Streaming サポートでは Node.js の Stream への対応に必要な最小限の変更だけが行われたので、オプションを有効化して Stream を返すだけで使えます。
早速複数のシナリオで試していくわけですが、まず HTTP Streaming を有効化するには app.setup を呼び出して enableHttpStream を true に設定する必要があります。
import { app } from "@azure/functions";
app.setup({ enableHttpStream: true });
ちなみに 1 回だけ呼び出せばよいので setup.ts のようなファイルを作成して、そこに上のコードを追加することで対応しました。これでグローバルに有効化されます。
ここから先に紹介するサンプルコードの注意点として、私自身が Node.js の Stream API に詳しいわけではないので効率の悪い実装になっている可能性はあります。
Blob を Streaming でダウンロード・アップロードする
まずはよくありそうなシナリオとして 1,2 位を争いそうな、Azure Storage の Blob に対して Stream でのダウンロードとアップロードを行ってみます。Blob SDK 自体は Node.js の Stream に対応しているので、HTTP Streaming を組み合わせると効率よく扱えるはずです。
用意したサンプルコードは以下のようになりました。HttpResponseInit の body に直接 readableStreamBody を渡すだけで良いと思っていましたが、TypeScript の型エラーが出てしまったので Readable.from を使って Readable に変換することで対応しました。
正直なところ Readable / ReadStream / ReadableStream の違いはよく分かっていません。
import { app, HttpRequest, HttpResponseInit, InvocationContext } from "@azure/functions";
import { BlobServiceClient } from "@azure/storage-blob";
import { Readable } from "stream";
const blobServiceClient = BlobServiceClient.fromConnectionString(process.env.AZURE_STORAGE_CONNECTION_STRING);
export async function httpTrigger1(request: HttpRequest, context: InvocationContext): Promise<HttpResponseInit> {
context.log(`Http function processed request for url "${request.url}"`);
const containerClient = blobServiceClient.getContainerClient('streaming');
const blobClient = containerClient.getBlockBlobClient('download.jpg');
const response = await blobClient.download();
const stream = Readable.from(response.readableStreamBody);
return {
body: stream,
headers: { 'Content-Type': 'image/jpg' }
};
};
app.http('httpTrigger1', {
methods: ['GET'],
authLevel: 'anonymous',
handler: httpTrigger1
});
これまでのように arrayBuffer や blob として一度メモリに読み込んでから返すのと違い、 Stream はすぐに応答を返し始めるので TTFB が短縮されます。更にメモリに全データを読み込まないので、消費するメモリ量は非常に少なくなります。
次はアップロードを行っていきますが、Blob SDK では Stream 用の API が用意されているので、こちらもダウンロードと同様にサクッと対応可能です。
現在の HTTP Streaming 実装はリクエストのペイロードしか対応していないので、マルチパートで送信されたファイルでは HTTP Streaming が使えない点に注意が必要です。アップロードでも uploadStream に直接 request.body を渡すことが出来なかったので、一度 Readable.from を経由して解決しています。
import { app, HttpRequest, HttpResponseInit, InvocationContext } from "@azure/functions";
import { BlobServiceClient } from "@azure/storage-blob";
import { Readable } from "stream";
const blobServiceClient = BlobServiceClient.fromConnectionString(process.env.AZURE_STORAGE_CONNECTION_STRING);
export async function httpTrigger2(request: HttpRequest, context: InvocationContext): Promise<HttpResponseInit> {
context.log(`Http function processed request for url "${request.url}"`);
const containerClient = blobServiceClient.getContainerClient("streaming");
const blobClient = containerClient.getBlockBlobClient("upload.jpg");
await blobClient.uploadStream(Readable.from(request.body));
return { body: 'Done' };
};
app.http('httpTrigger2', {
methods: ['POST'],
authLevel: 'anonymous',
handler: httpTrigger2
});
ダウンロードと同様にアップロードされたファイルが Stream で扱われるので、実行中の消費メモリ量が非常に少なく済むことを確認出来ました。パフォーマンスとスケーラビリティに大きく影響する部分なので、今後は可能な限り Stream を使っていきたいです。
Server-Sent Events を実装する
HTTP Streaming をサポートしたということは、ファイルを効率よく扱うだけではなく、Azure Functions でも Server-Sent Events が実装できるようになったことを意味します。公式ブログでも Azure OpenAI の Streaming が用途として挙げられていたように、処理中に順次応答を返すことが出来るようになりました。
WebSocket でも同じことは実現出来ますが、Azure Functions Runtime では有効化されていないようです。YARP 自体は対応しているので実装の都合という感じはあります。
しかしサーバーからクライアントに順次データを返すだけであれば Server-Sent Events が一番簡単です。
応答として Node.js の Stream を返せばよいだけなので、実現方法はいくつも考えられると思いますが、以下のサンプルコードでは Generator を作成して Readable.from で変換するようにして対応しました。
import { app, HttpRequest, HttpResponseInit, InvocationContext } from "@azure/functions";
import { Readable } from "stream";
const sleep = (timeout: number) => new Promise(resolve => setTimeout(resolve, timeout))
export async function httpTrigger3(request: HttpRequest, context: InvocationContext): Promise<HttpResponseInit> {
context.log(`Http function processed request for url "${request.url}"`);
const generator = async function* (count: number) {
for (var i = 0; i < count; i++) {
yield `event: ping\ndata: ${new Date().toISOString()}\n\n`
await sleep(1000)
}
};
const stream = Readable.from(generator(10));
return {
body: stream,
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-store'
}
};
};
app.http('httpTrigger3', {
methods: ['GET'],
authLevel: 'anonymous',
handler: httpTrigger3
});
このサンプルコードを EventSource を使って動かすと、以下のようにイベントが一定間隔でサーバーから送信されていることが確認出来ます。Generator が完了すると接続が切れて再接続が走るため、エラー発生時には明示的に close するコードを入れています。
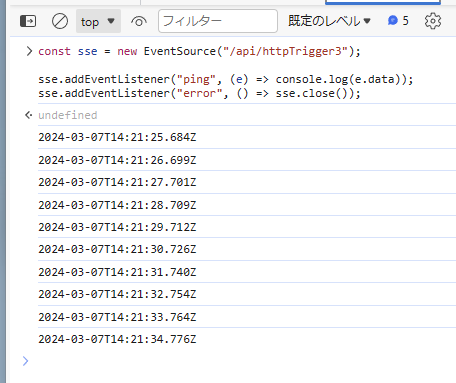
C# で言うところの CancellationToken に相当するものがなさそうなので、現時点の実装では SSE の送信中に接続が切れたことを判別する手段が無さそうです。なのでかなり長い期間接続を保持して、ダラダラとイベントを送信するようなケースでは対応が難しそうです。
Azure OpenAI の Streaming API と組み合わせる
ここまでの確認で準備が整っているので、最後は Azure OpenAI の Streaming API を使って Chat Completions の実行結果を Streaming でクライアントに返す実装を試してみます。Azure OpenAI のドキュメントでも最適化として Streaming が推奨されているので、Azure Functions でサクッと実装できると嬉しい部分です。
コードとしては Server-Sent Events を実装した時とほぼ同じで、違いとしては Generator の実装が EventStream<ChatCompletions> を引数で受け取って for await で回すようにしているだけです。
import { app, HttpRequest, HttpResponseInit, InvocationContext } from "@azure/functions";
import { OpenAIClient, AzureKeyCredential, ChatCompletions, EventStream } from "@azure/openai";
import { Readable } from "stream";
export async function httpTrigger4(request: HttpRequest, context: InvocationContext): Promise<HttpResponseInit> {
context.log(`Http function processed request for url "${request.url}"`);
const client = new OpenAIClient(process.env.AZURE_OPENAI_ENDPOINT, new AzureKeyCredential(process.env.AZURE_OPENAI_KEY))
const events = await client.streamChatCompletions(
'gpt-4',
[
{ role: 'system', content: 'You are an AI assistant that helps people find information.' },
{ role: 'user', content: 'Azure Functions について分かりやすく説明してください' }
],
{ maxTokens: 1024 }
);
const generator = async function* (events: EventStream<ChatCompletions>) {
for await (const event of events) {
for (const choice of event.choices) {
if (choice.delta?.content === undefined) {
continue;
}
console.log(choice.delta?.content);
yield `event: text\ndata: ${choice.delta?.content}\n\n`
}
}
};
const stream = Readable.from(generator(events));
return {
body: stream,
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-store'
}
};
};
app.http('httpTrigger4', {
methods: ['GET'],
authLevel: 'anonymous',
handler: httpTrigger4
});
このコードを実行してみると、応答が開始されるまでは少し時間がかかりますが、その後は Server-Sent Events として GPT-4 の応答が Streaming で流れていることが確認出来ます。Azure Functions をベースとしているので必要なコードが少なく実現出来ているのは大きなメリットです。
特に Azure OpenAI を利用したアプリケーションは多くの API が必要となるケースが少ないため、Azure Functions の HttpTrigger を使ってサクッと用意するのが手っ取り早いです。
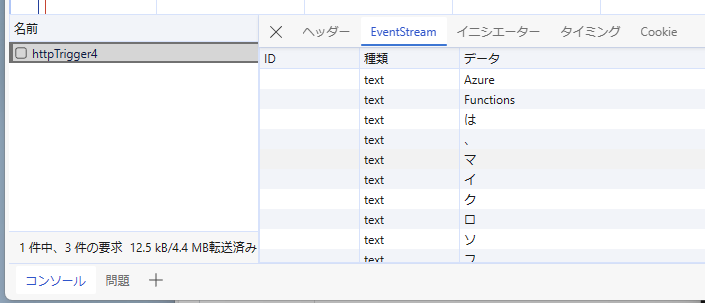
今回は Azure にデプロイまでは試していませんが、ほぼ全てのリージョンで Azure Functions Runtime の 4.30.0 以上がデプロイ済みなのですんなりと動作するはずです。あまり長い接続を作ろうとすると Azure Load Balancer のタイムアウトに引っかかる可能性はあるので、その辺りは注意が必要になります。
ちなみに Static Web Apps の Managed Functions にも 4.30.0 以上がデプロイされているはずなので、SWA でも利用できる可能性があります。Azure OpenAI と SWA の相性は良いと思っているので、組み合わせて使っていきたいです。